
Una vez que hemos resuelto los retos, vamos a analizar dos tipos de arquitecturas para procesamiento en tiempo real. Es importante mencionar que se construyen, generalmente, con componentes distribuidos desarrollados sobre la JVM y, por tanto, son soft real time systems. La principal diferencia entre ambas son los flujos de tratamiento de datos que intervienen y el paradigma de programación predominante. En su concepción juega un papel muy importante la madurez de las tecnologías existentes en cada momento.
Arquitectura Lambda
En su artículo “How to beat the CAP theorem” (2011) [1], Nathan Marz presenta la Arquitectura Lambda. Una arquitectura capaz de obtener resultados en tiempo real en sistemas con ingesta continua de datos y tolerante a fallos, tanto humanos como de hardware. Además, pretende prevenir la complejidad que produce el teorema del CAP en los Sistemas Distribuidos y, con esta prevención, “vencerlo”. Para Nathan, un sistema de datos se define de forma muy sencilla:
Consulta= Función (todos los datos)
El resultado de esta consulta es la combinación de los datos procesados por los paradigmas streaming y batch. Aunque existen sistemas para realizar este tipo de consultas contra PetaBytes de datos, son excesivamente costosos en recursos y no son el enfoque más eficaz. Para resolverlas de una forma más eficiente introduce la idea de calcular previamente los resultados con un conjunto de vistas y consultar estas vistas. La arquitectura está dividida en tres partes: batch layer (capa de batch processing), serving layer (capa de consulta) y speed layer (capa de stream processing). El funcionamiento es el siguiente:
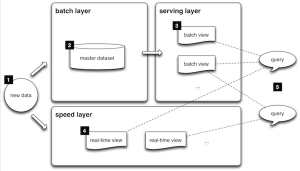
- Los nuevos datos ingestados por el sistema se envían tanto a la batch layer como a la speed layer para su procesamiento. Para este cometido suele usarse Kafka.
- Batch layer. Gestiona el conjunto de datos maestros en bruto y añade los nuevos datos a los ya existentes, que no se modifican. Mantiene, por tanto, una copia inmutable y creciente de todos los datos ingestados por el sistema. Al conjunto total de datos del sistema les aplica procesamiento batch en un proceso que puede llevar horas. El resultado son las batch views, que se usarán en la serving layer para ofrecer la información ya transformada al exterior. Estas vistas precalculadas se actualizan con cada iteración del procesamiento batch. La información suele almacenarse en HDFS y procesarse con Hadoop/Spark.
- Serving layer. Su misión es indexar las batch views (estáticas) y exponerlas de forma que puedan ser consultadas de forma óptima y en tiempo real. En esta capa suele haber una base de datos distribuida que responda a unas necesidades de escrituras cíclicas y de lecturas aleatorias. Aparecen bases de datos como HBase y Cassandra.
- Speed Layer. La batch layer no soluciona totalmente las necesidades de procesamiento. La latencia que generan las batch views hace que en el momento en el que finaliza su ejecución, el sistema ya tiene nuevos datos que no están representados en los resultados de la serving layer y, por tanto, las respuestas del sistema ante las consultas están desactualizadas. El análisis de la información que no está representada todavía en la serving layer es la misión de la speed layer. Para conseguir tiempos de respuesta instantáneos aplica algoritmos rápidos e incrementales a los datos recientes. Los resultados de estos cálculos, stream views, se actualizan en tiempo real a medida que se reciben nuevos datos. Una vez que los datos han sido procesados por la batch layer, y por tanto los resultados están disponibles en la serving layer, esa parte de la información de la stream view ya no es necesaria y se puede eliminar. Esta característica dota a la arquitectura de tolerancia a fallos funcionales de la speed layer (la más compleja), descartando el estado de la stream view y procesando todos los datos en la batch layer. Suelen aparecer tecnologías como Storm, Spark Streaming, Flink, Redis y Cassandra.
- Finalmente, la respuesta a las consultas realizadas al sistema se construye combinando los resultados de las batch views y de las stream views. Esta combinación es específica de cada sistema que implementa la arquitectura. Por ejemplo, se pueden almacenar las vistas en dos bases de datos: una optimizada para el tiempo real y otra optimizada para las actualizaciones batch. Ambas compartirían un registro único de la información (y meta información) que gestionaría las respuestas del sistema a las consultas. La lógica para combinar los datos de ambas vistas depende de las operaciones que implican las funciones a calcular para obtener las respuestas. Si las operaciones cumplen la propiedad asociativa (cálculos como la suma, el máximo, filtros o agrupaciones), la capa de combinación se limita a ejecutar las funciones sobre los datos agregados. Si las funciones requieren operaciones más complejas, debe utilizarse la meta información generada en los procesamientos anteriores.
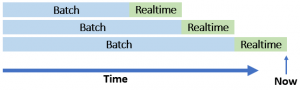
Actualización serving layer y speed layer
La Arquitectura Lambda incide en dos conceptos fundamentales en los sistemas de procesamiento intensivo de datos en tiempo real: la inmutabilidad de los datos históricos y la capacidad de reprocesar los datos almacenados en el sistema. Es básico que el sistema siempre genere sus resultados a partir del dato en bruto y que tenga la capacidad de recomputar la información existente. La necesidad de reprocesar los datos puede ser motivada por una optimización del proceso, solucionar un fallo o simplemente porque cambien las consultas al sistema y se necesiten nuevos cálculos. Como principal desventaja presenta el problema de administrar y monitorizar dos sistemas distribuidos complejos: batch y streaming. Obliga a mantener la lógica de la aplicación en dos paradigmas de programación diferentes y divergentes.
Arquitectura Kappa
El término Arquitectura Kappa fue introducido en 2014 por Jay Kreps en su artículo “Questioning the Lambda Architecture” [2]. En este artículo, Jay comenta sus pensamientos sobre la Arquitectura Lambda, con sus pros y sus contras, y describe su experiencia implementando la arquitectura de procesamiento en tiempo real de LinkedIn. La visión de Jay parte de una premisa: el paradigma principal de procesamiento es el streaming y las operaciones batch, son un subconjunto de las operaciones de streaming. Recordemos que un flujo de datos en stream no tiene ni un comienzo ni un fin desde un punto de vista temporal (unbounded). Es necesario acotarlo para obtener un flujo batch (bounded). Apoyándose en el paralelismo de los sistemas de procesamiento en streaming, propone una arquitectura en cuatro pasos:
- Kafka o una aplicación similar para la ingesta de datos y el almacenamiento de los datos susceptibles de ser reprocesados. Se pueden volcar los datos a HDFS (disco) si hay limitaciones de memoria.
- Un flujo de procesamiento en streaming cuyos resultados se almacenan en una tabla asociada. La aplicación cliente realiza consultas a esta tabla. Si es necesario reprocesar los datos, se inicia un segundo flujo de procesamiento para obtener una nueva tabla con los datos recomputados.
- Cuando la nueva tabla está lista, la aplicación empieza a leer de dicha tabla, que es alimentada por el segundo flujo de procesamiento.
- Se eliminan tanto el primer flujo de procesamiento como su tabla asociada.
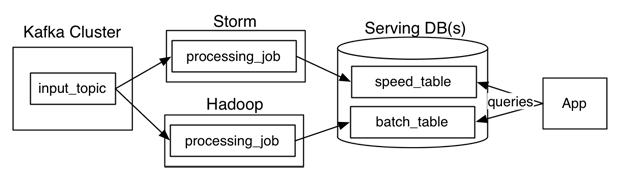
Esta visión subsana los posibles puntos “débiles” de la Arquitectura Lambda y la simplifica eliminando la capa batch. Podemos afirmar que sus tres pilares principales son los siguientes:
- Inmutabilidad de los datos. Se garantiza que los eventos se leen y almacenan en el orden en el que se han generado. La información de origen no se modifica, los datos son almacenados sin ser transformados.
- Solo existe un flujo de procesamiento, el de tiempo real. Este hecho produce que el código de programación,el mantenimiento y las actualizaciones del sistema se vean reducidos considerablemente. Sin embargo, los modelos necesarios para generar las vistas precomputadas son más complejos que los empleados en la speed layer de la Arquitectura Lambda, y su entrenamiento, mucho más costoso.
- Posibilidad de volver a lanzar un procesamiento. Un estado concreto puede ser recalculado a posteriori partiendo de una misma versión de los datos. Cuando se necesita recomputar la información por un cambio en la lógica del negocio o en el código de la aplicación, se ejecuta la nueva función sobre el motor de stream processing que lee la información almacenada en el sistema y crea una nueva tabla con los resultados.
Conocidas ya las principales diferencias entre ambas arquitecturas es necesario un criterio que permita elegir entre una u otra. Si la lógica de nuestro procesamiento en batch es distinta a la lógica de nuestro procesamiento en streaming, optaremos por una Arquitectura Lambda, si la lógica es similar, por una Arquitectura Kappa. Por cierto, para Jay el teorema del CAP se mantiene intacto al no ser “vencido” por la Arquitectura Lambda.
Hemos repasado brevemente los fundamentos de las arquitecturas de datos y parte de la “oferta” disponible en open source. A esta oferta habría que sumar distribuciones privadas y el catálogo de las grandes plataformas de Cloud Computing (Amazon, Google y Microsoft). Ahora viene la parte más compleja, elegir la arquitectura de datos adecuada para nuestro negocio o problema. Al igual que comentábamos con las bases de datos, no hay una arquitectura que sea buena para todos los casos (no one-size-fits-all). Debemos entender el problema, valorar los recursos con los que contamos y buscar el equilibrio entre todos los conceptos que ya conocemos.
«Lo que nos distingue a los humanos es nuestra capacidad de crear herramientas para amplificar nuestras capacidades»
Steve Jobs
Bibliografía
[1]: Marz, N. (2011). How to beat the CAP theorem, recuperado de: http://nathanmarz.com/blog/how-to-beat-the-cap-theorem.html
[2]: Kreps, J. (2014). Questioning the Lambda Architecture, recuperado de: https://www.oreilly.com/ideas/questioning-the-lambda-architecture
Fuente: Alejandro Rodríguez García, alumno del Máster en Big Data de MBIT School

