
El desarrollo de Internet en los últimos años ha propiciado la irrupción de nuevos modelos de negocio, con origen digital y muy centrados en el cliente. Estos modelos utilizan arquitecturas de datos tan pegadas al negocio que el propio mercado está basado en las capacidades de la arquitectura. La ventaja competitiva de las empresas que las emplean es la posibilidad de dar respuesta en tiempo real a las necesidades de sus clientes, de los que tienen un conocimiento extremo, saben: qué, cuándo, cómo y por qué.
La base para conseguirlo, un tratamiento excelente de los datos. En este escenario, las exigencias de análisis y extracción de valor de la información son cada vez mayores y con un marco temporal cada vez menor. Aparece el reto de gestionar con Velocidad los datos.

Actualmente, analizar los datos en el mismo instante en el que se generan se ha convertido en una necesidad para muchas empresas. Recomendaciones de productos o servicios, comportamiento de clientes, Internet de las Cosas, monitorización de dispositivos médicos, ciberseguridad, detección de fraude, son algunos ejemplos de casos de uso en los que es necesario procesar datos en tiempo real, como y cuando vienen, para poder tomar decisiones con la mayor rapidez posible. A esta necesidad de obtener valor de los datos en tiempo real, o cerca del tiempo real, responden las soluciones de streaming.
Una de las mejores definiciones de streaming es la de Tyler Akidau, de Google: “a type of data processing engine that is designed with infinite data sets in mind. Nothing more”. Mientras que en el procesamiento batch tenemos un conjunto de datos limitado (bounded) con un principio y un final, y el trabajo termina tras procesar este conjunto, en el procesamiento en streaming nos enfrentamos a flujos de datos sin límites (unbounded) que llegan al sistema que los tiene que procesar en pequeñas cantidades y de forma continuada. A los ítems de información que llegan al sistema los denominamos eventos, datos, mensajes o records. Al conjunto de ítems con forma de flujo infinito y continuo, lo denominamos stream de datos.La problemática que conlleva gestionar este tipo de flujos es mayor que la necesaria para gestionar un sistema batch.
Comenzaremos este artículo definiendo los principales conceptos asociados al procesamiento de streams de datos. Después, analizaremos las principales opciones existentes en el ecosistema streaming: herramientas como Storm, complementos de tecnologías existentes como la librería de Streaming de Sparky, un framework diseñado específicamente para streaming como es Apache Flink. Por último, describiremos Kafka, pieza fundamental en las arquitecturas de tiempo real (y de micro servicios).
Tipos de procesamiento de eventos
La forma de procesar los eventos quizás sea la característica más importante de un sistema de streaming. Define sus propiedades y casos de uso. Hay dos estrategias:
- Native streaming (streaming puro). Los eventos son procesados uno a uno, en el momento en el que llegan, sin esperar a otros.
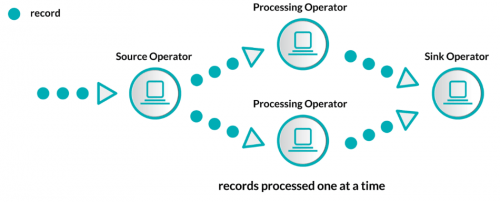
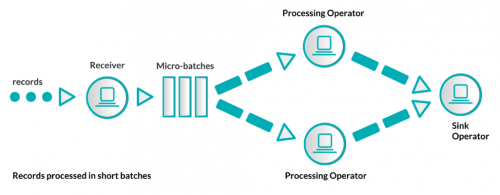
- Micro–batching (o fast-batching). Es una evolución del procesamiento enbatch. Los eventos se agrupan en lotes pequeños y atómicos, por cantidad o por tiempo, para posteriormente ser procesados.
Rendimiento: latencia y throughput
Toda aplicación de streaming debería estar diseñada para tratar cada evento en origen tan pronto como sea recibido. La cantidad y la velocidad de procesamiento determinan el rendimiento. Dos conceptos importantes:
- Throughput. Es la cantidad de información neta que fluye a través de un sistema. Se mide en eventos procesados por segundo en el sistema. Cuanto más alto, mejor.
- Cuánto tarda un evento en ser procesado. Es la suma de los retardos temporales producidos en los procesos de transmisión, transformación y análisis de la información. Cuanto más baja, mejor.
Semántica de procesamiento
Con el término semántica nos referimos a la consistencia de la transmisión de eventos desde el origen hasta el destino en el que se procesarán. Para solventar los problemas que pueden producirse en la transmisión existen varias estrategias, más o menos eficientes, que denominamos garantías de entrega:
- Exactamente una vez (exactly once). Asegura que los eventos ni se pierden ni se duplican. La estrategia más difícil de implementar ya que implica la gestión del estado del sistema.
- Al menos una vez (at least once). Asegura que los eventos no se pierden, pero puede haber duplicados. Es el modelo más práctico cuando la pérdida de eventos no es aceptable.
- Como mucho una vez (at most once). Asegura que los eventos no se duplican, pero pueden perderse. Es el comportamiento más sencillo de implementar. Estrategia válida en modelos en los que la pérdida de datos no es un problema.
Gestión de estado: stateless y stateful
Desde la perspectiva de los datos, el estado puede definirse como la información necesaria para el procesamiento correcto de un evento. Podemos identificar dos tipos:
- Stateless (sin estado). El procesamiento de cada evento es independiente del resto de eventos. Ejemplos: map, filter, join con datos estáticos, etc.
- Stateful (con estado). El procesamiento de cada evento depende del resultado de los eventos procesados previamente, depende del estado. Es necesario mantener dicho estado en un almacenamiento que se actualice periódicamente. Ejemplo: sumatorios de eventos por clave.
Si la solución de streaming tiene capacidad para mantener el control del estado es de tipo stateful, si carece de ella, es de tipo stateless. En este segundo caso, la gestión del estado recae en la aplicación que utiliza la solución.
Tolerancia a fallos
El estado desde la perspectiva de los datos no es el único que debe gestionar la solución de streaming. Para garantizar tolerancia a fallos, en soluciones stateless o stateful, es necesario controlar el estado de todo el sistema: fuentes de datos, canales de comunicación y procesos.Es decir, almacenar y actualizar la información mínima esencial para que el sistema pueda recuperarse después de fallos como pueden ser un corte de red, un error de memoria o la caída de un nodo.
Storm
Fué creado originalmente por Nathan Marz y su equipo de BackType en 2010. Más tarde fue adquirido y devuelto a la comunidad por Twitter convirtiéndose en un proyecto Apache top level en 2014. Fue el pionero (y estándar de facto) en el campo de procesamiento masivo de datos en stream. Es un sistema de streaming nativo provisto de una API de bajo nivel. Está compuesto por dos tipos de componentes:
- Spouts, responsables de la ingestade datos en el sistema desde diversas fuentes de origen.
- Bolts, operadores encargados de transformar y procesar los datos.
Con estos componentes se crea una topología, una estructura de spouts y bolts, por la que fluye el stream de datos produciéndose su procesamiento. Este modelo de operadores continuos presenta problemas para el control del flujo, bajo throughput, semántica de procesamiento at least once, gestión de estado statelessy un elevado overhead.
Spark Streaming
Spark es el estándar de facto para el procesamiento batch. Spark Streaming es el componente desarrollado sobre Sparkpara responder a las necesidades de procesamiento en streaming. Se puede hablar de un punto de inflexión a partir de la versión 2.0 de la librería. Mientras que la versión 1.x está limitada a procesamiento basado en micro batchs, el Structured Streaming de la versión 2.0 constituye el primer paso en la evolución hacia un motor de streaming de baja latencia con soporte total a una semántica basada en eventos individuales. Es decir, supone el salto del processing time al event timemanteniendo características como: escalabilidad, tolerancia a fallos, garantías de entrega exactly once, gestión de estado statefuly alto throughput.
Apache Flink
Tiene su origen en la iniciativa de investigación “Stratosphere: Information Manegement on the Cloud” en la que colaboraron varias universidades del área de Berlín. A finales de 2014 fue aceptado como proyecto top level de Apache. Actualmente está soportado por la start-upVerverica. Flink [1] es un framework para el procesamiento de datos en streaming. Sus principales características son:
- Procesamiento en streaming Cuenta con características avanzadas para garantizar resultados precisos, incluso en el caso de eventos desordenados (out-of-order) o tardíos.Se puede utilizar para procesamiento en batch, como caso acotado del streaming.
- Es 10 veces más rápido que Hadoop MapReduce procesando en disco y 100 veces más rápido si puede procesar en memoria.
- Con el fin de mejorar el rendimiento y soportar iteraciones (necesarias en el procesamiento de grafos y en MachineLearning), tiene su propio gestor de memoria dentro de la JVM.
- Se caracteriza por su alto throughput, baja latencia, escalabilidad (a miles de nodos), gestión de estado stateful[2] y garantía de entrega de mensajes exactlyonce. Utiliza el algoritmo AsynchronousBarrierSnapshotting [3], diseñado para garantizar la tolerancia a fallos mediante
- Contiene librerías para el procesamiento de datos mediante lenguaje SQL, Machine Learning y análisis de grafos.
Dentro del “mundo” de los frameworks de procesamiento distribuido batch/streaming, a pesar de su menor madurez, Flink es el rival natural de Spark. Lo utilizan empresas como: Alibaba, ING, BouyguesTelecom,Ericsson, Huawei, Uber o Zalando.
Apache Kafka
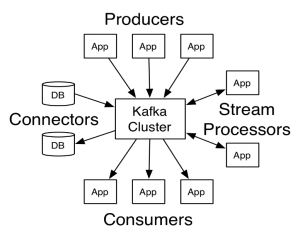
Es un framework distribuido de streaming. En origen fue desarrollado por LinkedIn que lo publicó como opensource en 2011. En noviembre de 2014, varios ingenieros que trabajaron en el proyecto Kafka de LinkedIn crearon una nueva empresa, Confluent, enfocada a desarrollarlo. Basado en un modelo editor/suscriptor,es tolerante a fallos y masivamente escalable. Estas características, unidas a su baja latencia y alto rendimiento, lo convierten en una herramienta excelente para comunicar streams de información que se generan a gran velocidad y que deben de ser gestionados por una o varias aplicaciones. Puede verse como una cola de mensajes que almacena streams de records (clave, valor y sello de tiempo) en categorías llamadas topics. Los procesos que publican mensajes (editores) se denominan brokers y los suscriptores son los consumidores de los topics. Tiene cuatroAPIs para entenderse con Producers (editores), Consumers (suscriptores de uno o varios topics), Connectors (aplicaciones o bases de datos) y Stream Processors (aplicaciones que la utilizan para transformar datos).
Ya conocemos la forma de resolver el tercero de los retos que plantea el universo digital a las Arquitecturas de Datos. Hemos completado el recorrido por las Vs de Data. En la siguiente entrega combinaremos los retos para describir las Arquitecturas de Datos de referencia: Lambda y Kappa.
<< Entrada anterior: Las Vs de Data: Volumen
Bibliografía
[1]: Carbone, P., Katsifodimos, A., Ewen, S., Markl, V., Haridi, S., and Tzoumasz, K. (2015). Apache Flink: Stream and Batch Processing in a Single Engine, IEEE Data Engineering Bulletin 38, pp. 28-38.
[2]: Carbone,P., Ewen, S.,Fóra, G., Haridi, S., Richter, S., and Tzoumas, K. (2017). State management in Apache Flink®: consistent stateful distributed stream processing, Proceedings of the VLDB Endowment, Volume 10 Issue 12, pp. 1718-1729.
[3]: Carbone, P., Fóra, G., Ewen, S., Haridi, S., and Tzoumas, K. (2015). Lightweight Asynchronous Snapshots for Distributed Dataflows, arXiv preprint arXiv:1506.08603.
Fuente: “Arquitecturas de Datos, de Hadoop a Beam” por Alejandro Rodríguez García, alumno del Máster en Big Data de MBIT School.

